This post is part of a small series of articles on using Pulumi to leverage CloudFront and Lambda@Edge for on the fly image resizing. The code for this part can be found here and here.
- Pulumi, CloudFront & Lambda@Edge: Introduction
- Pulumi, CloudFront & Lambda@Edge: Infrastructure
- Pulumi, CloudFront & Lambda@Edge: Lambda
- Pulumi, CloudFront & Lambda@Edge: Deployment
In this part, we will set up a deployment pipeline using GitHub Actions so that we can automate the deployment of the infrastructure defined in the previous articles. To enable secure deployments in AWS, we first set up an OpenID Connect provider in AWS. After enabling GitHub Actions for deployment in AWS with OIDC, we will define the GitHub Actions workflows to set up the AWS infrastructure and create and deploy the AWS Lambda functions. At the end, we will discuss options to improve the pipeline.
Configuring OpenID Connect in AWS
As of October 2021, GitHub supports OpenID Connect (OIDC) for secure deployments in the cloud. With this feature, we can use short-lived tokens that are automatically rotated with each deployment instead of storing long-lived AWS credentials in GitHub. In this section, we will create the necessary resources in AWS to enable secure cloud deployment workflows without requiring cloud secrets stored in GitHub. We won’t go into too much detail on how this works, but you can find a lot of information on this topic, e.g. here, here, and here. Nonetheless, below we will describe the required resources that need to be created using Pulumi to enable secure deployments within GitHub Actions in AWS. The code associated with this section can be found here
The first resource we need to enable deployments of GitHub actions in AWS is the OIDC provider itself.
let openIdConnectProviderArgs = OpenIdConnectProviderArgs(
Url = "https://token.actions.githubusercontent.com",
ClientIdLists = inputList [input "sts.amazonaws.com"],
ThumbprintLists = inputList [input "6938fd4d98bab03faadb97b34396831e3780aea1"])
let openIdConnectProvider = OpenIdConnectProvider("GithubOidc", openIdConnectProviderArgs)
let federatedPrincipal =
GetPolicyDocumentStatementPrincipalInputArgs(Type = "Federated", Identifiers = inputList [ io openIdConnectProvider.Arn])
In addition to the OIDC provider, we need to create a policy where we define the allowed actions that we can perform in our deployment workflow. For our example, we need access to CloudFront, S3, Lambda, and IAM. In a real project, a good practice would be to disregard access to all resources with the “*” operator and define only the actions that are really needed, applying the Principle of Least Privilege.
let cloudFrontPolicy =
let cloudFrontStatement =
GetPolicyDocumentStatementInputArgs(
Actions = inputList [ input "cloudfront:*";
input "s3:*";
input "lambda:*";
input "iam:*"],
Resources =
inputList [ input "*" ]
)
let policyDocumentInvokeArgs =
GetPolicyDocumentInvokeArgs(
Statements =
inputList [ input cloudFrontStatement ]
)
let policyDocument =
GetPolicyDocument.Invoke(policyDocumentInvokeArgs)
let policyArgs =
PolicyArgs(PolicyDocument = io (policyDocument.Apply(fun (pd) -> pd.Json)))
Policy("cloudFrontPolicy", policyArgs)
Last, we create a role that can be used by our deployment pipeline that tells AWS IAM that this role can be taken by GitHub actions in our repository. It is important to define the condition in the policy document statement to restrict access to the desired repository. Otherwise, any workflow in GitHub could take over this role.
let githubActionsRole =
let assumeRoleWithWebIdentityStatement =
GetPolicyDocumentStatementInputArgs(
Principals =
inputList [ input federatedPrincipal ],
Actions = inputList [ input "sts:AssumeRoleWithWebIdentity" ],
Conditions = inputList [
input (GetPolicyDocumentStatementConditionInputArgs(
Test = "StringLike",
Variable = "token.actions.githubusercontent.com:sub",
Values = inputList [ input "repo:simonschoof/lambda-at-edge-example:*"]
))
]
)
let policyDocumentInvokeArgs =
GetPolicyDocumentInvokeArgs(
Statements =
inputList [ input assumeRoleWithWebIdentityStatement ]
)
let policyDocument =
GetPolicyDocument.Invoke(policyDocumentInvokeArgs)
Role("githubActionsRole",
RoleArgs(
Name= "githubActionsRole",
AssumeRolePolicy = io (policyDocument.Apply(fun (pd) -> pd.Json)),
ManagedPolicyArns = inputList [ io cloudFrontPolicy.Arn])
)
Deployment pipeline with GitHub Actions
Now that we have the OIDC provider in place, we can start to define our deployment pipeline to build and deploy the Lambda functions and CloudFront. At the end, we want to be able to achieve a CI/CD workflow. To this end, we will define the following tasks in our pipeline:
- Creating the viewer request function
- Create the origin response function
- Create or update the Lambda@Edge and CloudFront environment in AWS using Pulumi
As mentioned earlier, the first task is to build the viewer request function. To do this, we just need to set up a Node.js environment, install the dependencies, and build the function. At the end, we upload the artifacts as build output with a predefined action. Since uploading and later downloading the artifacts takes quite a long time, it probably would have been better to use the caching mechanism of GitHub Actions.
name: Deploy CloudFront with Lambda@Edge
on:
workflow_dispatch:
branches:
- main # Set a branch to deploy
concurrency: cloudfront_deployment
jobs:
build-viewer-request:
name: Build viewer request
runs-on: ubuntu-latest
defaults:
run:
working-directory: lambda/viewer-request-function
steps:
- uses: actions/checkout@v3
- uses: actions/setup-node@v3
with:
node-version: 14.x
- name: Install dependencies
run: npm ci --ignore-scripts
- name: Build function
run: npm run build
- uses: actions/upload-artifact@v3
with:
name: viewer-request-function
path: lambda/viewer-request-function/dist/
In parallel with the first task, we can also create the origin response function. As we saw in the
previous article
, the original response function uses the Sharp library, which requires the libvips native extension. This means that we need to create and package the function for the Lambda execution environment. We can also do this in the deployment pipeline using the Amazon Linux Docker image and the defined Dockerfile. An interesting detail in creating the origin response function is to use the npm ci command with the -ignore-scripts flag. We want to use this flag to protect us from supply chain attacks. As a result of the flag, we need to rebuild the Sharp library after the npm ci command. A more detailed description of this issue and how to prevent it can be found here. Finally, we upload the output of the install and build command using the predefined upload action.
build-origin-response:
name: Build origin response
runs-on: ubuntu-latest
defaults:
run:
working-directory: lambda/origin-response-function
steps:
- uses: actions/checkout@v3
- name: Install dependencies and build function
run: |
docker build --tag amazonlinux:nodejs .
docker run --rm --volume ${PWD}:/build amazonlinux:nodejs /bin/bash -c "source ~/.bashrc; npm init -f -y; rm -rf node_modules; npm ci --ignore-scripts; npm rebuild sharp; npm run build"
- uses: actions/upload-artifact@v3
with:
name: origin-response-function
path: |
lambda/origin-response-function/dist/
lambda/origin-response-function/node_modules
In the last part, we want to create or update the Lambda@Edge functions and CloudFront instance in AWS. This job will only run if both functions have been successfully created from the previous jobs. Within the job, we only need to perform the following steps:
- Download the viewer request and origin response build artifacts using the respective download action
- Configure the AWS credentials assuming the role we defined in the first section of this article
- Run
Pulumi upwith the pulumi action
Note that the job will take quite a bit of time, as the changes need to be propagated to the edge locations of the CloudFront instance. We also need to provide an access token for Pulumi, which is stored as a GitHub secret.
deploy:
name: Deploy CloudFront & Lambda
needs:
- build-viewer-request
- build-origin-response
if: success()
permissions:
id-token: write
contents: read
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- uses: actions/download-artifact@v3
with:
name: viewer-request-function
path: lambda/viewer-request-function/dist
- uses: actions/download-artifact@v3
with:
name: origin-response-function
path: lambda/origin-response-function
- uses: actions/setup-dotnet@v2
with:
dotnet-version: 6.0.x
- name: Configure AWS Credentials
uses: aws-actions/configure-aws-credentials@master
with:
aws-region: eu-central-1
role-to-assume: arn:aws:iam::424075716607:role/githubActionsRole
role-session-name: GithubActionsSession
- uses: pulumi/actions@v3
with:
work-dir: ./pulumi
command: up
stack-name: dev
env:
PULUMI_ACCESS_TOKEN: ${{ secrets.PULUMI_ACCESS_TOKEN }}
After the pipeline completes successfully, we can start uploading images to S3 and providing the links for the images through the CloudFront domain. The users of the images can also specify the resizing parameters to get the resized images on the fly.
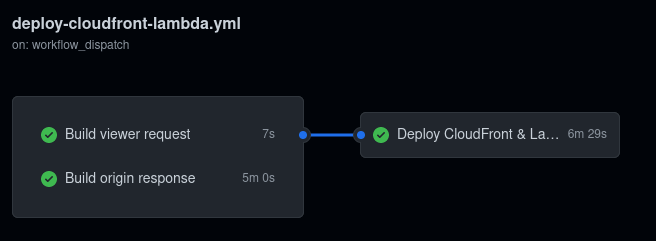
Github Actions deployment pipeline
Conclusion
Finally, we have reached the first version of our deployment pipeline, and we are now able to continuously integrate and deploy our resizing function. Nevertheless, this first version is not optimal and would probably fail a proper continuous integration certification. The first reason is the lack of testing, which makes it almost impossible to continuously deliver or deploy the application. Unless you don’t mind not knowing if the application is still working as it was intended, or if it is running at all. The second reason is the overall run time of our pipeline. If we want to be able to roll back our changes within 10 minutes, we need to optimize the runtime of our pipeline. If we look at the long-running tasks in our pipeline, we can easily identify some tasks that could be optimized:
- Uploading and downloading the origin response function takes quite a long time. We could possibly optimize this by using a different approach to sharing data between jobs, e.g. perhaps caching
- We could also optimize the trigger for creating the functions and only create them when the functions have changed, but not when we have only updated the CloudFront configuration.
Another point to consider is that when using the upload and dowload artifact actions, GitHub stores the artifacts for the pipeline run. For private repositories, GitHub only provides a certain amount of storage, so it would be a good idea to delete the executed artifacts after the pipeline has completed successfully.
Another tedious task is the propagation of changes to the edge sites. Unfortunately, this is not a part that we can optimize ourselves; we rely on AWS for this.
Nonetheless, we now have a first working version of our deployment pipeline, which is a good starting point for the optimization and further development of the application.